$ pip install tensorboard
from torch.utils.tensorboard import SummaryWriter
writer_dict = {
'writer': SummaryWriter(log_dir="../output/log/"),
'train_global_steps': 0,
'valid_global_steps': 0,
}
for epoch in range(start_epoch, end_epoch)
***
학습코드
***
writer = writer_dict['writer']
global_steps = writer_dict['train_global_steps']
writer.add_scalar('train_losses', train_losses.avg, global_steps)
writer.add_scalar('train_acc', train_avg_acc, global_steps)
writer_dict['train_global_steps'] = global_steps + 1
***
평가코드
***
writer = writer_dict['writer']
global_steps = writer_dict['valid_global_steps']
writer.add_scalar('valid_losses', valid_losses.avg, global_steps)
writer.add_scalar('valid_acc', valid_avg_acc, global_steps)
writer_dict['valid_global_steps'] = global_steps + 1
writer_dict['writer'].close()
$ tensorboard logdir="../output/log/"
writer.add_image("image_name", img_grid)
writer.add_graph(net,images)
writer.add_scalar('Train', Loss_val, global_step)
writer.add_scalar('Train', Loss_val, global_step)
writer.add_figure('pred Vs target', fig, global_step)
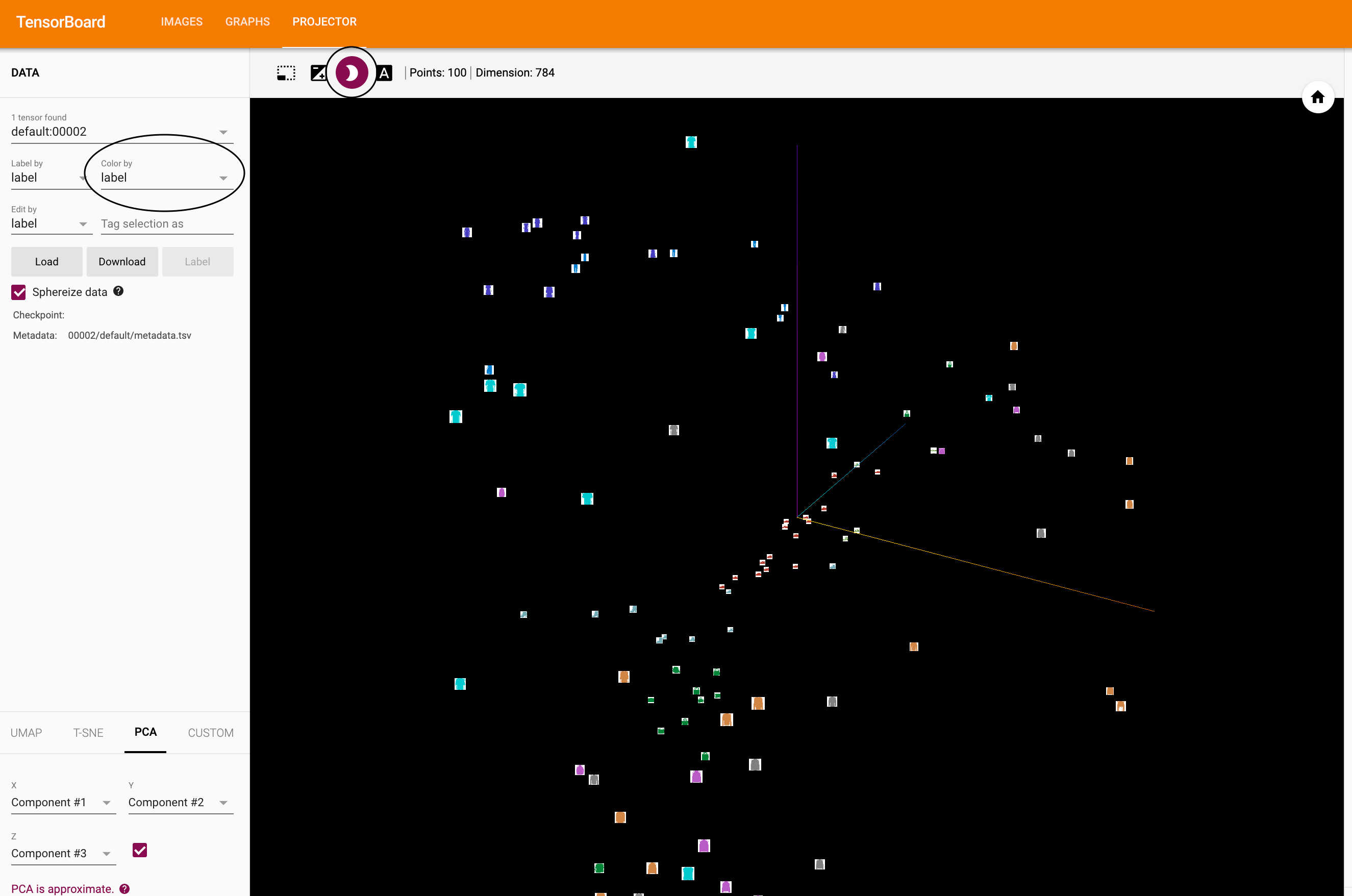
def select_n_random(data, labels, n=100):
'''
데이터셋에서 n개의 임의의 데이터포인트(datapoint)와 그에 해당하는 라벨을 선택합니다
'''
assert len(data) == len(labels)
perm = torch.randperm(len(data))
return data[perm][:n], labels[perm][:n]
# 임의의 이미지들과 정답(target) 인덱스를 선택합니다
images, labels = select_n_random(trainset.data, trainset.targets)
# 각 이미지의 분류 라벨(class label)을 가져옵니다
class_labels = [classes[lab] for lab in labels]
# 임베딩(embedding) 내역을 기록합니다
features = images.view(-1, 28 * 28)
writer.add_embedding(features,
metadata=class_labels,
label_img=images.unsqueeze(1))
writer.close()