
BlazePose
BlazePose : On-device Real-time Body Pose tracking
BlazePose 논문 리뷰를 위해 의역하여 작성.
Abstract
BlazePose는 모바일에서 Human Pose Estimation을 Real-Time으로 실행하기 위한 lightweight Convolution Neural Network Architecture다.
Network는 Single Person의 33개의 Body Keypoint를 추론하고, Pixel2 스마트폰에서 30FPS 이상으로 실행된다. 특히 Fitness Tracking / Sign Language Recognition과 같은 Real-Time 사례에 적합하다.
새로운 Body Pose Tracking Solution과 Lightweight Body Pose Estimation Neural Network를 제공하고, 이러한 Network는 Keypoint Coordinates를 찾기 위해 Heatmap과 Regression 둘다 사용한다.
Introduction을 들어가기 전에 간단히 추가 설명 하면, BlazePose의 주된 아이디어는 Body Pose Tracking과 Heatmap/Regression 두가지를 통한 학습방식이다. 이를 통해 높은 정확도와 Real-Time을 구현한다.
1. Introduction
Image / Video를 통한 Human Body Pose Estimation은 다양한 Application에서 중심적인 역활을 한다. (ex. health tracking, sign language recognition, and gestural control) 이러한 작업은 매우 다양한 포즈, 수많은 자유도, 폐색(Occlusion) 때문에 어렵다. 최근 연구들은 Pose Estimation에서 상당한 진전을보여준다. 일반적인 접근법은 각 좌표의 Offset을 수정하기 위해 각 Joint마다의 Heatmap을 만드는것이다. Heatmap 방식은 최소한은 Overhead로 Multi Person으로 확장이 가능하자만, Single Person에 대해서는 모바일에서 Real-Time으로 추론하기에 모델이 상당히 크다.
Heatmap 기반 접근법과 달리, Regression 기반 접근법은 계산량이 더 적고 확장성이 더 높지만, 평균 좌표 값을 예측하려고 시도하며 애매한 포즈를 해결하지 못한다. Newell이 제안한 방식은 Hourglass Architecture를 쌓아서 작은 파라미터에서도 예측에 대한 상당한 퀄리티 향상 보여줬다. BlazePose는 이러한 아이디어를 확장하여 모든 Joint의 Heatmap을 예측하기 위해 Encoder-Decoder Network Architecture를 사용한다. 따라오는 또 다른 Encoder는 모든 Joints의 Coordinates를 직접 회귀추정한다.
즉, Encoder-Decoder Network로 Heatmap을 학습시키고, 또 다른 Encoder로 Regression하여 각 관절 좌표를 예측한다. 이렇게 하면, 추론중에 Heatmap Branch를 제거할수 있어 모바일에서 Real-Time으로 돌아갈수 있도록 모델이 가벼워진다.
2. Model Architecture and Pipeline Design
2.1. Inference pipeline
BlazePose는 추론중에 Detector-Tracker를 사용한다. Detector-Tracker는 hand landmark prediction / dense face landmark prediction과 같은 다양한 Task에서 Real-Time으로 실행할수 있도록 도와준다. Pipeline은 아래의 그림과 같이 Lightweight Body Pose Detector 다음으로 Pose Tracker Network가 실행된다. Tracker는 Keypoint Coordinate와 현재 프레임에 사람이 존재하는지 예측하고 현재 프레임의 ROI를 수정한다. Tracker가 사람이 없다고 판단하면, Detector는 다음 프레임에서 다시 실행된다.
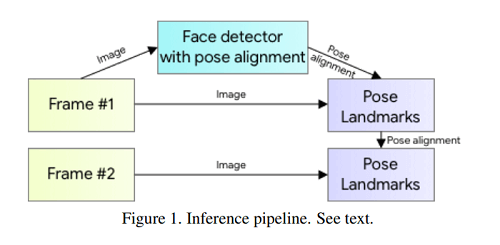
2.2. Person detector
대부분 최근 Object Detection Solutions은 마지막 후처리 단계에서 Non-Maximum Suppression(NMS) 알고리즘에 의존한다. NMS는 자유도가 거의 없는 강성 Object에서 잘 동작한다. 하지만, 사람들 간의 악수 / 포옹과 같은 겹치는 동작의 경우 잘 작동하지 않는다. 왜냐하면, 모호한 여러상자의 IoU(Intersection over Union) Threshold를 만족하기 때문이다.
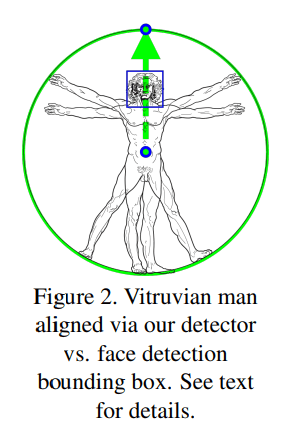
이를 극복하기 위해, Body Part중에서 잘 변하지 않는 얼굴 / 몸통을 Detection 하는데 초점을 두었다. 또한 사람의 얼굴이 대조가 크고 변화가 적어 Network에서 강력한 신호를 준다는것을 경험적으로 관찰했다. 사람을 빠르고 가볍게 탐지하기 위해서, Single Person의 경우 항상 머리가 보일것이라는 가정했다.
결과적으로, Pose Detector 대신에 빠른 On-Device Face Detector를 사용한다. Face Detector는 추가적으로 Person Alignment Parameters를 예측한다. (Prarmeters : Mid Hip Keypoint / 사람을 둘러싸는 원의 크기와 기울기 (Mid Hip과 Mid Shoulder 두점을 잇는 선 기울기) )
2.3. Topology
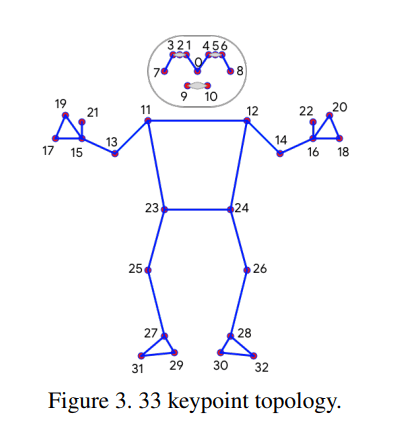
BlazePose는 BlazeFace, BlazePalm, Coco Dataset에 포함된 33개의 Keypoint를 새로운 Topology를 제시한다. OpenPose와 Kinect Topology와는 다르게, BlazePose는 차후 확장된 모델 Region of Interest(ROI)의 Rotation, Size, Position을 추정하기 위해 Face, Hands, Feet의 최소한의 Keypoint만 사용한다.
Face, Hands, Feet의 최소한의 Keypoint는 확장된 모델의 보조 Keypoint가 된다. 이 보조 Keypoint를 활용해서 확장된 모델 Region of Interest(ROI)의 Rotation, Size, Position을 추정하는 것이다.
2.4. Dataset
대부분의 Heatmap Base방식과 달리 BlazePose의 Tracking Base는 Initial Pose Alignment가 필요하다. 이를 위해 전신이 보이거나 Hips과 Shoulders Keypoint가 명확히 Annotation 될 수 있는 Dataset으로 제한했다. 또한 Dataset에 존재하지 않는 무거운 Occlusion에 도움을 주기위해, Occlusion Augmentation도 진행하였다.
Training Dataset은 평범한 포즈의 Single / Few People 60K Images와 Fitness장면의 Single Person 25K Images로 구성되어 있다. 모든 이미지는 사람에 의해 Annotation 되었다.
2.5. Neural network architecture
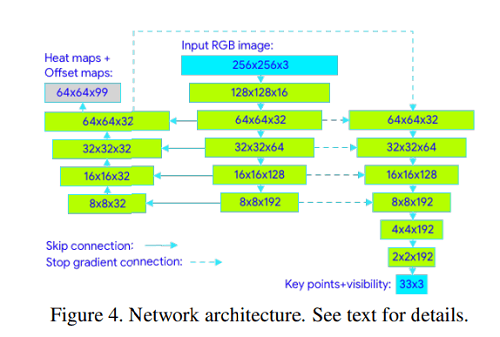
BlazePose는 아래의 Figure 4. 같이 결합된 Heatmap / Offset / Regression 접근법을 사용한다. Heatmap과 Offset Loss는 Training Staget에서 사용한다. 그리고 추론을 실행하기 전에 해당하는 모델의 Output Layer를 제거한다. Lightweight Embedding인 Regression Encoder Network를 Supervise하기 위해 Heatmap을 효율적으로 사용한다. 이러한 접근법은 Newell의 Stacked Hourglass 접근법에 부분적으로 영감을 받았고, 작은 Encoder-Decoder Heatmap Base Network와 그 다음 따라오는 Regression Encoder Network을 Stack하는 방식을 적용했다.
그리고 high and low level features의 밸런스 때문에 Skip-Connections을 모든 Stage에서 적극적으로 활용한다. 그러나 Regression Encoder의 Gradient는 Heatmap Trained Feature로 Backpropagation 되지 않게 한다. 이것은 Heatmap 예측을 향상시킬 뿐만이 아니라 Regression 정확도도 증가시킨다.
2.6. Alignment and occlusions augmentation
BlazePose는 Augmentation하는 동안 Angle, Scale, Translation을 제한하고, 이를통해 Network Capacity를 줄여 호스트 장치에서 더 적은 계산 및 에너지 자원을 요구하는 동시에 네트워크를 더 빠르게 만든다. Detection Stage 또는 Previous Frame Keypoints 중 하나의 기반으로, Hips 사이의 Keypoint가 Network Input으로 들어갈 정사각현 이미지 중심에 위치하도록 사람을 Align한다. 이를 위해 Mid-Hip 과 Mid-Shoulder 사이의 Line($L$)을 가지고 Rotation을 추정하고, 추정된 Rotation을 통해 Y-Axis와 평행하게 회전한다. Scale은 모든 Body Points가 Square Bounding Box안으로 들어오도록 추정된다. 게다가 10% Scale과 Shift Augmentaions을 적용하여, Tracker가 프레임과 왜곡된 Alignment 사이에서도 잘 동작할수 있도록 한다.
Invisible Points 예측을 돕기위해 Training 동안 Occlusion Augmentaion(다양한 색으로 채워진 Random Rectangles)을 실행한다. 그리고 특정한 Point가 가려졌는지 그리고 Position 예측이 부정확한지 나타내는 각 Point의 Visbility Classifier를 도입한다. 이를 통해 상반신 또는 대부분의 몸이 상당히 가려진 상황에서도 지속적으로 Person Tracking을 진행할 수 있다.

3. Experiments
모델의 퀄리티를 평가를 하기위해, OpenPose를 Baseline으로 선택했다. 평가하기 위해 수동으로 2개의 내부 Dataset을 Annotation했다. 내부 데이터에는 1-2명의 사람이 있는 1000개의 이미지가 있다. AR Dataset이라 불리는 첫번째 Dataset에는 일상의 매우 다양한 사람의 포즈가 있다. 반면에 두번째 Dataset에는 Yoga와 Fitness 포즈로 구성되어 있다. 평가를 할때는, 일관성 있게 평가하기 위해서 BlazePose와 MSCOCO에 공통적으로 들어있는 17 Points를 사용한다. 평가 Metric으로 Percent of Correct Keypoints(PCK@0.2)를 사용한다. 인간의 기준을 확인하기 위해, 두명의 Annotator에게 AR Dataset을 다시 Annotaion하도록 요청했고, 97.2 PCK@0.2를 얻었다. (인간의 Annotaion과 AR Dataset의 오차를 보고싶었던듯)
PCK@0.2는 Ground thruth - Predict 간의 2D Euclidean Error가 사람의 Torso size의 20%보다 작을 경우 옳게 Detection되었다고 가정한다.
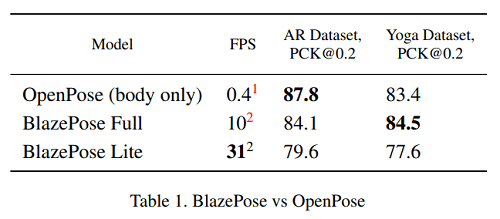
BlazePose는 용량이 다른 두개의 모델을 같는다. ( BlazePose Full (6.9 MFlop, 3.5M Params) / BlazePose Lite (2.7 MFlop, 1.3M Params) ) 이러한 두 모델은 아래의 그림과 같이 AR Dataset에서 OpenPose 모델보다 약간 낮은성능을 갖지만, BlazePose Full 모델의 Yoga/Fitness Dataset의 경우 OpenPose보다 더 나은 성능을 보여준다. 동시에, BlazePose의 Single mid-tier phone CPU와 OpenPose의 20Core의 Desktop CPU와 비교하면 BlazePose가 25-75배 더 빠른 성능을 보여준다.
4. Applications
Sign Language, Yoga/Fitness Tracking 및 AR과 같은 다양한 성능 요구 사용 사례에 사용하기 위해 Single Person Human Pose Estimation 모델을 개발했다. 이 모델은 Mobile CPU에서 Real-Time에 가깝게 작동하고, mobile GPU에서는 CPU보다 Latency를 눈에 띄게 줄일수 있다. 33개의 Topology는 BlazeFace와 BlazePalm과 함께 구성되어 있으며, 이후 활용 예제에서, Hand Pose와 Facial Geometry Estimation 모델의 Backbone이 될 수 있다.
이 접근방식은 기본적으로 더 많은 Keypoint 수 / 3D 지원 / 추가적인 Keypoint 속성(Visibility 같은걸 말하는듯) 으로 확장될수 있고, Heatmap/Offsetmap 기반이 아니기 때문에 새로운 각 Feature Type 당 추가적인 Full-Resolution Layer가 필요하지 않는다.
3D / 추가적인 Keypoint 속성 확장은 Heatmap/Offsetmap 방식에서 학습하지 않고 Regression에서 추가 학습하기 때문에 Heatmap/Offsetmap의 Feature Resolution Layer가 필요하지 않다는 뜻인 듯.
5. 정리
BlazePose의 가장 큰 장점은 정확도를 최대한 유지하면서 빠른속도를 내는것이다. 이를 위해 학습된 Heatmap의 Encoder 정보를 이용하여 Regression 학습에 이용하였고, 그결과 Mobile에서 돌아갈수 있을 정도의 속도를 얻었다.
또한, 고질적인 NMS Algorithm문제를 해결했으며, 다른 Network에 비해 속도가 많이 느린 Detection에 Tracking을 이용하여 초기 한번만 실행하고, 이후로는 Pose Estimation만 실행하도록 한다. Detection 보조 Keypoint와 Pose Estimation 실행 후 나온 Landmark Keypoint로 Tracking을 진행하며, Tracking 중 사람이 존재하지 않을경우 다시 처음인 Tracking Step부터 실행한다.
BlazePose는 정확도에만 치중된 논문과는 다르게, 새로운 아이디어로 최대한의 효율을 이끌어낸 좋은 논문이라고 생각된다. 이를 바탕으로 다양한 Task에 적용이 가능할 것이라고 생각된다.