
BlazeFace
BlazeFace : Sub-millisecond Neural Face Detection on Mobile GPUs
BlazeFace 논문 리뷰를 위해 의역하여 작성.
Abstract
BlazeFace는 모바일에 최적화된 모델이다. 플래그쉽 스마트폰에서 200-1000+ FPS까지 나오며, Face Region Segmentaion / Facial Features or Expression Classification / 2D/3D Facial Keypoint or Geometry Estimation 같은 정확한 얼굴영역이 필요한 다양한 작업에 적용할 수 있다.
모델 구조는 MobileNetV1/V2에서 영감을 받았지만 다른 구조를 사용한다. 또한 SSD에서 수정된 anchor 방식을 사용하고, non-maximum suppression 대신에 개선된 tie resolution strategy를 사용한다.
1. Introduction
최근, 깊은 네트워크에서 다양한 모델 개선으로 인해 Real-Time Object Detection이 가능해졌다. 그러므로 모바일에서 가능한 빠르게 동작해야하며, Real-Time 벤치마크 성능보다 더 높아야한다.
그래서 BlazeFace는 모바일 GPU Inference에 최적화된 모델을 제안한다. SSD(Single Shot Multibox Detector) 모델구조를 변형하며, 주된 기여는:
1. Inference Speed 관련:
1.1 Lightweight Object Detection을 위해 특별히 제작된, MobileNet V1/V2 구조와 관련된 매우작은 CNN 모델
1.2 GPU를 효과적으로 사용하기 위한, SSD에서 수정된 새로운 Anchor 구조 (Anchor = Priors(SSD 전문용어)이고 네트워크 예측을 조절하는데 사용하며, 미리 만들어둔 정적경계상자이다.)
2. Predict Quality 관련: 중첩된 예측 사이에 부드러운 tie resolution과 안정감을 얻기위해 non-maximum suppression 대신에 개선된 tie resolution strategy를 사용한다.
2. Face detection for AR pipelines
BlazeFace는 모바일 카메라에서 얼굴을 Detection하는데에 초점을 둔다. 모바일의 정면과 후면카메라의 서로다른 Focal Length와 일반적으로 캡처된 오브젝트 크기 때문에 분리된 모델을 구축한다.
뿐만 아니라, axis-aligned face rectangles을 예측한다. BlazeFace 모델은 얼굴 회전(roll angle)을 추정할수 있도록 6개의 Facial Keypoint Coordinates를 만든다. (eye centers, ear tragions, mouth center, and nose tip) 이는 회전된 얼굴 박스를 비디오 프로세스 파이프라인의 후속 작업단계에 전달할 수 있고, 후속 처리단계에서 translation과 rotation invariance을 완화시킨다. (얼굴의 회전을 추정하고, align하여 rotation에 대한 Complexity를 완화시킨다는 뜻인거 같음.)
3. Model architecture and design
BlazeFace의 모델 구조는 아래에 논의된 4가지 중요한 디자인을 고려사항을 중심으로 구축되었다.
Enlarging the receptive field sizes.
최근 CNN구조는 모델 그래프 전곳에 $3×3$conv Kernels을 선호하는 경향이 있는 반면에, BlazeFace는 Depthwise Seperable Convolution을 주목한다. Depthwise Seperable Convolution의 연산의 대부분은 Pointwise연산이 차지한다. 예를 들어, $s×s×c$ input tensor에서 $k×k$ Kernel을 갖는 Depthwise Conv 처리하기 위해 필요한 연산량은 $s^2ck^2$이다. 반만에 그 다음에 오는 Pointwise Conv 연산은 $d$ channel을 output으로 갖는 $1×1$ conv은 $s^2cd$의 연산량으로 구성된다. Pointwise 연산은 Depthwise 연산 대비 $d/k^2$배 만큼 연산량을 갖는다.
실제로, Metal Performance Shaders을 실행한 iPhone X에서 16-bit floating point 연산 $3×3$ Depthwise Conv은 $56×56×128$ tensor의 경우 0.07ms 걸린다. 반면에 그 다음 오는 128에서 128 채널로 $1×1$ Conv하는 경우 0.3ms보다 4.3배 느리다.
정리하자면, Depthwise Seperable Convolution은 Depthwise + Pointwise Conv이며, 기존 Convolution 연산보다 낮은 연산량을 갖는다.
Depthwise는 input tensor가 $s×s×c$라고 했을 때, $k×k×1$ Kernel c개를 가지고 인풋의 채널 별로 1대1 대응하여 연산을 한다. ($k×k×1$ Kernel이 인풋 채널과 같은 c개의 채널을 갖고있으므로, $s×s×c_i$ 와 $k×k×c_i$와 같이 대응되어 연산된다.) 이때, $s^2ck^2$의 연산량이 필요하다. (Padding=SAME, Stride=1일 경우, 이때 아웃풋은 인풋과 모양이 같다.)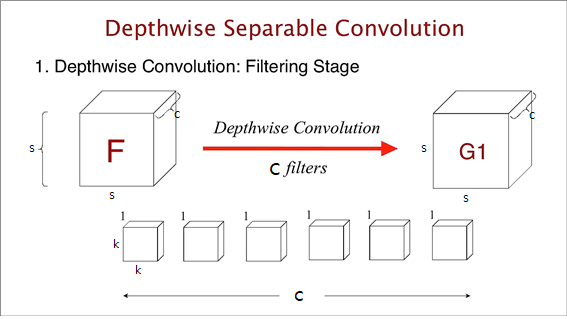
Pointwise의 경우 input tensor가 $s×s×c$이고, $1×1×c$ Kernel을 가지고 연산이 진행된다. 위에서 $d$ channel을 output으로 가지므로, $1×1×c$ Kernel을 $d$개 만큼 갖는 conv가 진행되고, $s^2cd$의 연산량이 필요하다.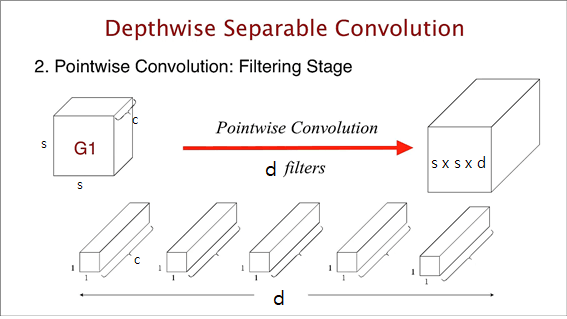
이때, Pointwise conv는 Depthwise conv보다 $d/k^2$배 만큼 연산량을 갖는다.
이것은 Depthwise part의 Kernel Size를 늘리는것은 상대적으로 더 가벼움을 의미한다. 그래서 BlazeFace에서는 Bottleneck 구조에서 $5×5$ Kernel을 사용한다. $5×5$ Kernel을 사용하므로써, 특정 Receptive field 크기에 도달하기 위한 레이어 갯수를 줄일 수 있다.
MobileNetV2 bottleneck에서는 depth-increasing(expansion, Pointwise Conv) -> Depthwise Conv -> depth-decreasing(projection, 비선형성에서 분리된 Pointwise Conv)이라는 Inverted Residual 구조로 진행한다. 반면에 BlazeFace는 중간 tensor에 매우 작은 채널을 적용하기 위해, bottleneck 구조에서 residual connections이 “expanded”(increased) 채널 resolution에서 수행하도록 단계를 바꾼다. 즉, depth-decreasing -> depth-increasing로 변경한다.
Depthwise Conv의 low overhead(추가적으로 사용되는 시간/메모리/자원)는 두 Pointwise Conv 사이에 또 다른 Layer를 도입할수 있도록 해준다. 이것이 Double BlazeBlock의 형태이다. Conv 갯수와 Bottleneck 유무에 따라 Single BlazeBlock과 Double BlazeBlock로 나뉜다.
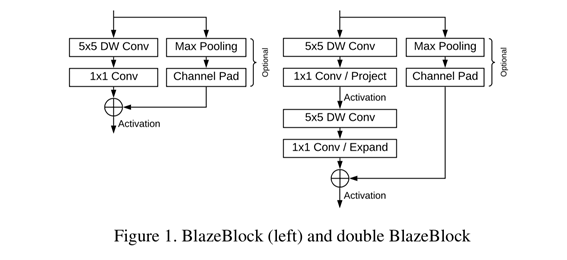
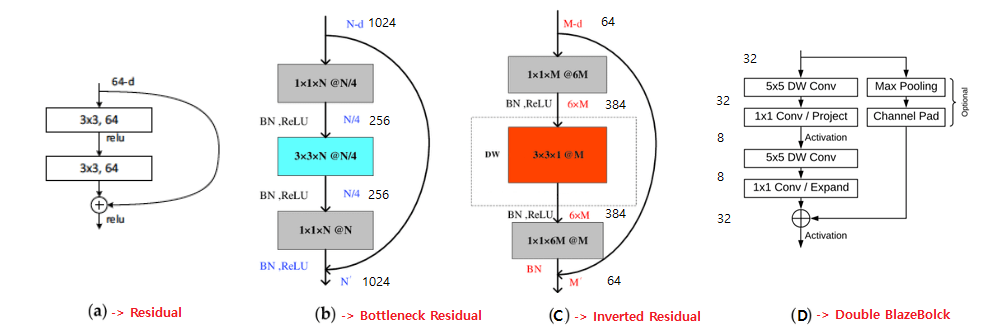
예시로 나온 다른 Block들과 비교를 해보면, Resnet논문에서는 Residual Block의 SkipConnection을 통해 Vanishing Gradient를 방지해 더 깊은 Network학습이 가능했다. Resnet-50 이상부터는 파라미터 갯수도 많이지고 깊이도 깊어져 Bottleneck 구조의 $1×1$Conv를 적용해서 연산량도 줄이고, Overffiting도 방지하였다. MobileNetv2에서는 DepthWiseSeperable Conv를 이용한 Inverted Bottleneck 구조를 사용하여 모바일에서도 돌아가도록 연산량을 줄였다. BlazeBlock은 위에서 말한것 처럼 MobileNetv2의 Inverted Bottleneck 구조를 변경하여 사용한다.
Feature extractor.
특정한 예를들기 위해, 정면 카메라 모델을 위한 Feature extractor에 초점을 둔다. 정면 카메라 모델은 더 작은 범위의 Object Scale을 다뤄서, 더 낮은 계산량을 요구한다. Extractor는 $128×128$ RGB이미지를 input으로 하고, 5개의 Single BlazeBlock과 6개의 Double BlazeBlock으로 구성되있다. 가장 높은 tensor depth는 96이고, 가장 낮은 spatial resolution은 $8×8$이다. (SSD는 $1×1$ resolution까지 줄인다.)
Anchor scheme.
SSD와 같은 Object Detection model들은 미리 정의한 고정된 사이즈의 Bounding Boxes에 의존한다.(Faster R-CNN에서 Priors or Anchors라고 불리는) Center Offset / Dimension Adjustments와 같은 Regression(and possibly classification) 파라미터는 각 Anchor에 대해 예측된다. 이것은 미리정의된 Anchor 위치를 타이트한 bounding rectangle로 조절하는데 사용된다.
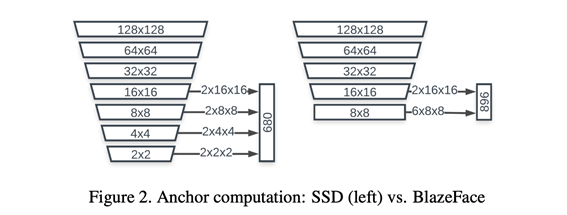
(Left)
Object Scale 범위에 따라서 여러 해상도에서의 Anchor를 정의하는 것이 일반적이다. Aggressive downsampling은 또한 계산 리소스 최적화를 위한 방법이다. 전형적으로 SSD 모델은 $1×1$, $2×2$, $4×4$, $8×8$, $16×16$ Feature map sizes의 예측을 사용한다. 그러나 Pooling Pyramid Network(PPN) 구조는 Feature map 해상도에 도달한 후에는 추가적인 계산이 불필요할수 있다는 것을 시사한다.
(Right)
이를 고려하여, 대안으로 Downsampling 없이 $8×8$ Feature map 차원에서 멈추는 Anchor 구조 채택하고, Figure 2와 같이 $8×8$, $4×4$, $2×2$ resolution의 각 2개의 Anchor를 $8×8$의 6개 Anchor로 교체한다. 사람 얼굴 모양의 제한된 비율로 인해, 가로 세로 1:1 비율로 제한된 Anchor는 얼굴을 정확히 Detection하는데 충분할 것이다.
Post-processing.
BlazeFace의 Feature Extractor는 $8×8$ 아래의 resolution으로 줄이지 않으므로, 겹치는 Anchor의 숫자는 Object Size에 따라 상당히 증가한다. 전형적인 non-maximum suppression에서, Anchor들 중 하나만 뽑고 최종 알고리즘 결과로 사용한다. 이러한 방식은 비디오 프레임에 적용될 때, 서로 다른 Anchor들끼리의 변동하여 예측하는 경향이 있고 jitter가 일어난다(사람이 감지할수 있을정도로).
이러한 현상을 최소화하기 위해, suppression 알고리즘을 blending strategy로 대체한다. blending strategy는 중첩된 예측 사이의 weighted mean을 함으로써 bounding box의 regression parameter를 추정한다. 이러한 방식을 사용함으로써 NMS 알고리즘에서 연산상 추가적인 비용도 들지 않고, 10% 정확도 향상을 보였다.
같은 input image에 약간의 offset 취하여 network에 통과하고 모델의 결과가 어떻게 영향을 끼치는지 관찰하여 jitter의 양을 측정했다. tie resolution strategy 전략 수정 후, jitter metric은 원본 이미지의 예측과 이동된 이미지 예측 사이의 root mean squared로 측정되며, 정면 카메라의 경우 40% 감소하였고 후면 카메라의 경우 30%의 감소를 보여줬다.
4. Experiments
BlazeFace 66K images Dataset에 대해서 학습했고, 직접만든 지역적으로 다양한 2K images Dataset으로 평가하였다. 정면 카메라 모델은 얼굴이 20%이상 차지하는 이미지로 구성되있다.(후면 카메라 모델의 경우 5%이상)
Regression parameter errors는 inter-ocular distance (IOD:눈 사이의 거리)에 의해 normailzation했고, median absolute error(중앙값 절대 편차)는 IOD의 7.4%로 측정되었다. 위에서 언급한 jitter metric은 IOD의 3%로 측정되었다.
아래의 Table 1은 average pricision(AP) metric / 정면 detection network의 mobile GPU inference time / 같은 Anchor 구조 사용한 MobileNetV2 Object Detector와의 비교를 보여준다.(MobileNetV2-SSD) 추론시간을 평가할 때, TensorFlow Lite GPU의 16-bit floating point 사용한다.
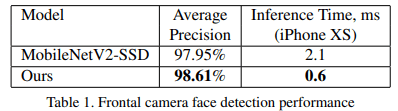
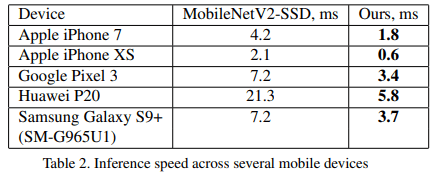
Table 2는 다양한 Flagship Devices에 대해 두 모델의 GPU inference speed 관점에서 보여준다.
5. Application
BlazeFace는 Full Image 또는 Video Frame을 실행하고, 모든 Face관련 Computer Vision Application에 첫 번째 단계로 사용될수 있다. (예를들어, 2D/3D Facial의 Keypoints / Contour / Surface Geometry Estimation / Features or Expression Classification / Region Segmentation.) 추정된 몇가지 Keypoint를 이용하여 crop된 얼굴이 가운데로 오도록 회전할수 있으며, scale normalize하고 roll angle을 0에 가깝게 만들 수 있다. 이것은 상당한 translation과 rotation invariance에 대한 요구사항을 제거하여, 더 나은 Computation Resource을 할당하도록 도와준다. (CNN에 대한 Complexity를 낮춰준다는 말 같음)
Face Contour Estimation을 특별한 예로 설명하면은, Figure 3에서는 BlazeFace 결과물로 6개의 얼굴 Keypoint와 Bounding Box를 보여주고(Red), 이것은 약간 확장된 Crop(Green)에 적용되므로 좀 더 복잡한 Face Contour Estimation Model에 Refine된다. 즉, Keypoint는 더 자세한 Bounding Box(Green)를 추정하고, 다음 프레임의 Face Detection Tracking을 위해 재사용 될 수 있다. 이러한 전략 실패를 감지하기 위해, Contours model은 얼굴이 존재하는지와 제공된 Rectangular Crop에 적절하게 Align되었는지 탐지한다. 이러한 조건을 위반할 때 마다, BlazeFace Detector는 다시 시작된다.
즉, Keypoint는 Face Align과 Tracking에 사용되므로써, 매 프레임마다 작동되는 것이 아닌, Tracking이 실패했을 때 처음으로 한번 시작되므로 Computation Saving이 가능하다.
![]()